
模型集成是基于模型设计开发的重要阶段,需要综合考虑集成模型架构的可读性、可测试性以及代码生成方式等因素,本文从架构设计和代码生成角度探一下模型集成中的几个常见问题。
架构设计
架构设计是相对复杂的话题,从实现角度来看两个常见的问题是层次不统一和架构模块类型选择不当。层次不统一指同一层模型中的包含不同颗粒度或不同类型的模型,如下图所示在同层模型中既有架构模块(subsystem)又有基本模块(gain),这种建模方法不仅影响模型的可读性,也混淆了子系统之间的界限。另外gain模块的参数采用了硬编码,不利于后期的维护,也不推荐使用,建议的方式是定义参数变量代替。

图1 混杂模块的模型集成
是否所有的基本模块都不能与架构模块置于同一层呢?也不尽然,一些用于信号路由的基本模块可以与架构模块并列,比如总线创建和选择模块、数据类型转换模块、信号合并模块等等,具体的使用规则可以参见MAAB建模规范db_0143。
架构模块包括库模块、虚拟子系统模块、实体(atomic)子系统模块和模型引用模块。常见的问题是在使用过程中形成固定选用一种模块的偏好,给后期的测试和维护代码麻烦。
库模块的特点是在不破坏关联的情况下修改算法时需要回到原库中修改,且一旦修改会影响所有使用该库模块的模型,因此常用于低频改动高频使用的成熟小算法场景,比如信号去抖算法等。而模型引用适用于高频改动的并行开发和集成场景,因其保持了接口和配置的独立性可用于承载单元(unit)级模块。虚拟子系统对多个模型引用形式的单元模块进行视觉封装,形成功能(feature)以提高系统集成的可读性,下图为模型集成的架构案例。
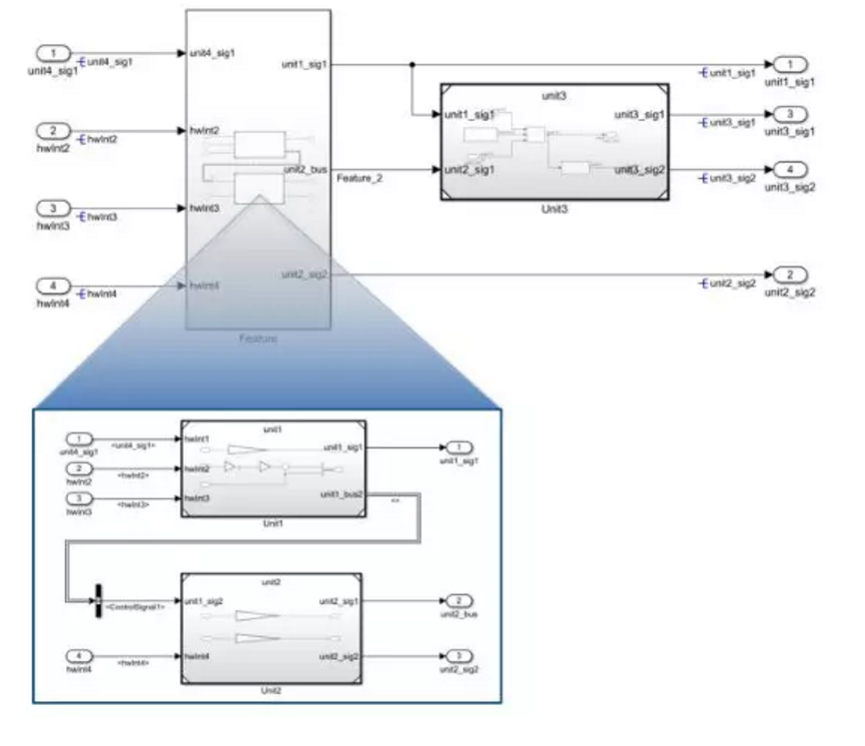
图2 模型集成的架构参考
代码生成
代码生成的常见问题是生成单位的选择:是在单元级模型生成还是在集成级模型生成?建议是在集成级模型生成,显而易见的好处是对共享函数的处理机制。在单元级模型生成时,默认情况下会生成同名的共享函数(如查表,定点等),集成时会发生冲突。
一种解决方法是为每个模型设置添加共享函数的命名方式,如添加后缀;或者将其独立生成到共享区,后续再经过后处理进行合并。而以集成级模型生成代码时,会自动处理共享函数问题,无需再进行后处理;至于集成级模型的代码生成速度问题,可以利用增量式生成或者并行生成降低生成时间。

图3 共享函数命名对比
除了架构设计和代码生成的考量外,模型集成还应考虑其他因素,如数据管理、接口设计以及功能安全等,这些内容以后有机会将在其他文章论述。
(PS:文章来源微信公众号 :基于模型设计(微信号:Model_Based_Design))
请登录后评论~